不同的编程语言有各自的内存管理方式:
- c/c++的内存堆空间的申请和释放完全靠自己管理.
- java依赖JVM实现内存管理,不了解JVM内存管理机制,很可能会因一些错误的代码导致内存泄漏或者内存溢出.
- python是通过私有堆空间管理内存的,所有python对象和数据结构都存储在私有堆空间中.一般程序员没有访问堆的权限,只有解释器可以操作,在python中”万物皆对象”,并且将内存操作封装的很好,所以python的基本数据类型所占的内存要远远大于纯数据类型结构所占的内存.例如,存储int型数据需要占据4字节的存储空间,但使用python申请一个对象来存放数据,所占用的空间要远大于4字节.
接下来以c++为例介绍编程语言的内存管理.
程序运行时所需的内存空间分为固定部分和可变部分,如:
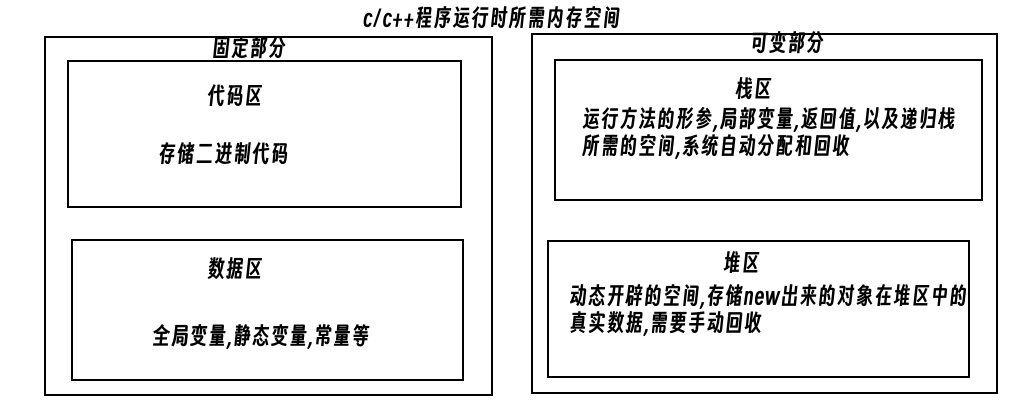
固定部分的内存消耗不会随着代码运行而产生变化,而可变部分会产生变化.
更具体一些,一个由c/c++编译的程序占用的内存分为以下几个部分:
- 栈区(Stark):由编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方法类似于数据结构中的栈
- 堆区(Heap):一般由程序员分配释放,若程序员不释放,则程序结束时可能由系统收回
- 未初始化数据区(Uninitialized Data):存放未初始化的全局变量和静态变量
- 初始化数据区(Initialized Data):存放已初始化的全局变量和静态变量
- 程序代码区(Text):存放函数体的二进制代码
代码区和数据区所占的空间都是固定的,而且占用的空间非常小,运行时消耗的内存主要取决于可变部分
堆区因是程序员自己开辟的空间,故释放要及时否则易造成内存泄露
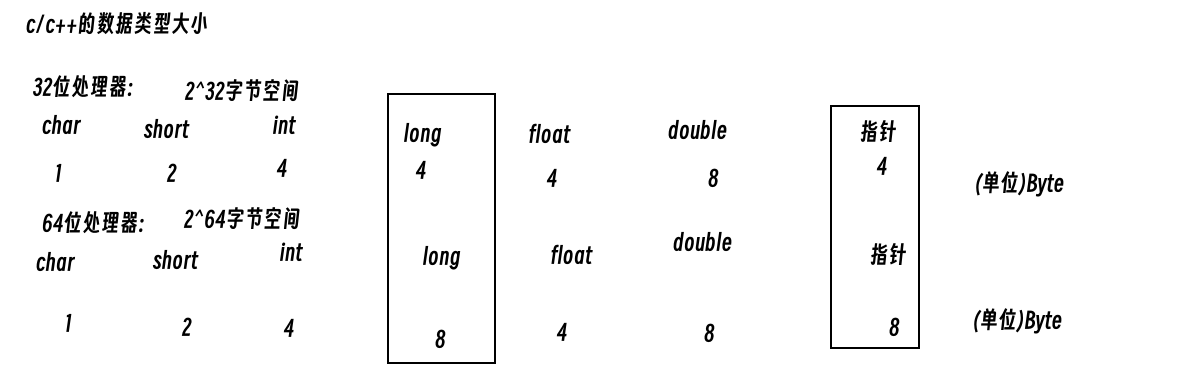
数据类型的大小:
cpu的内存空间为运存,而硬板则是外存,只发挥存储功能
为什么64位的指针占用8字节,而32位指针占用4字节?
1字节占8bit,4字节为32bit,32位处理器存储大小为2^32,即4GB的内存大小,故指针可以在4GB内查找
而64位编译器的存储大小为2^64,如果指针大小还是4字节,则不能遍历所有内存,故需要8字节
内存对齐:
所有跨平台语言均存在内存对齐:c/c++/python/java…
存在内存对齐的原因:
(1)平台原因:不是所有的硬件平台都能访问任意内存地址上的数据,某些平台只能在一些地址获取特定类型的数据,否则会抛出异常,为了使同一个程序可以在多平台上运行,需要内存对齐
(2)硬件原因:经过内存对齐后,CPU访问内存的效率大大提升
/**
* ClassName: ${NAME}
* package: ${PACKAGE_NAME}
* Description:
* @Author: innno
* @Create: 2024/2/27 - 21:54
* @Version: v1.0
*/
#include <bits/stdc++.h>
using namespace std;
struct node
{
int num;
char cha;
};
int main()
{
ios::sync_with_stdio(false), cin.tie(nullptr), cout.tie(nullptr);
int a[100];
char b[100];
cout << sizeof(int) << endl;
cout << sizeof(char) << endl;
cout << sizeof(a) << endl;
cout << sizeof(b) << endl;
cout << sizeof(node) << endl;
return 0;
}
输出结果:

此时发现,输出的结果和单纯的数字计算是有偏差的,这就是执行了内存对其的效果
下面分析内存对齐和非内存对齐产生的效果的区别
CPU读取内存时不是一次读取单个字节,而是按照块来读取的,块的大小可以是2,4,8,16字节,具体读取多少个字节取决于硬件
假设CPU把内存划分为4字节大小的块,要读取一份4字节大小的int型数据,来看一下两种情况下的CPU的工作量:
第一种是内存对齐的情况:

1字节的char占用了4字节的内存空间,空了3字节的内存地址,int数据从地址4开始.此时直接读取4,5,6,7处的地址即可.
第二种时非内存对齐的情况:

char类型和int类型挨在一起,该int型数据从地址1开始,CPU读取这个数据需要如下几步:
1:CPU读取0,1,2,3处的4字节的数据
2:CPU读取4,5,6,7处的4字节数据
3:合并地址1,2,3,4处后的4字节的数据才是本次操作需要的int型数据
此时一共需要两次寻址,一次合并的操作
虽说内存对齐多占用了一些资源,但是如今速度需要远大于内存需求,故用内存资源换速度